
What is a Loom?
- Chase Carter

- Dec 13, 2024
- 6 min read
When I say Kaleidoscope Research is “exploring the ‘textual multiverse’ implicit in large language models”, the first question is often, “...what?”. In this post I’ll explain some of the relevant background, what the ‘textual multiverse’ is, and what a Loom interface is. I’ll be glossing over some of the finer technical details to keep jargon at a minimum.
Background
Chat Interfaces
You’re probably familiar with the typical chat-based interaction paradigm used for large language models (LLMs) like ChatGPT and Claude[1]. In this paradigm, the language model has been specifically trained to assume a helpful ‘Assistant’ personality, and to reply to the user in a conversational format: User says something, Assistant responds, and so on. If you’ve ever started a conversation with ChatGPT over from scratch, with the same initial message (and a non-zero temperature), you may have noticed that ChatGPT’s replies are non-deterministic; in other words, you can get different responses from the exact same prompt.
In fact, this non-determinism applies to every single word[2] choice in the response, such that by the time you get to the end of a long response, the LLM has meandered through a potentially very path-dependent chain of word choices to arrive wherever it has arrived. Roll the dice again and you could get a very different result. Have you ever wondered about what might have been?
How can we answer questions like “how unlikely was this result?”, “is this result characteristic of the model’s typical behavior or is it an outlier?”, “do the possible behaviors of the model converge or diverge given such-and-such context?”, “what happens if I force the model into highly unlikely branches?”? While these questions could be explored clunkily by retrying requests over and over in a chat interface and manually copying and organizing the responses, or by setting up custom automated experiments in code, there is a better way that retains the fluidity and open-endedness of chat but also provides visibility into the diversity of possible responses.
Textual Multiverse
With some of the predominant methods used for LLM text generation currently, for any given prompt (and non-trivial output length) there are astronomically many possible completions. There’s nothing particularly special about the one you happen to get when you press ‘enter’ in a chat interface. One can imagine the other possible completions, branching out at each individual word, constituting a massive tree structure expanding outwards from the original prompt.
In the limit, this tree of words would contain every possible permutation of all words, which wouldn’t be a very useful data structure. But fortunately for us, LLMs, during their pre-training process, learn about the structure of language implied by human usage of language in their training dataset. Also implicit in this structure are facts or inferences (including sometimes incorrect inferences) about the context in which that language was developed and employed… which is to say, facts about the world and the humans in it. With this additional learned information, one can imagine assigning probabilities to each line between words in the tree, perhaps making more probable lines thicker and less probable lines thinner. Now we have a data structure that can actually do something useful: probabilistically generate syntactically correct & semantically meaningful text based on an initial context. Or, put another way, it can simulate as much of the underlying world model as the LLM was able to learn about.[3] This hypothetical branching data structure is the textual multiverse.[4]
Different LLM implementations have different training processes & different training datasets, and therefore different underlying world-models, so you might be wondering why we don’t say ‘textual multiverses’, plural. Technically the plural form would be accurate, however in practice it seems that as the models get larger and the datasets get bigger (approaching the total human output of recorded text), the world-models converge like different pixelated versions of the same underlying picture coming into focus.[5] From this perspective, ‘textual multiverse’ is an abstraction over all of language, not just over any given LLM or over the collection of existing LLMs. Much like the Library of Babel, it contains every document that has ever existed or could exist.
It’s difficult to see the landscape of the textual multiverse in a simple chat interface; it’s like trying to infer the detailed topography of the Himalayan Mountains from a single 2D vertical cross-section. This is where Loom interfaces shine. With a Loom interface you can catch a glimpse of the shimmering landscape of concepts and intelligence embedded in language, as implied by the distribution of possible LLM completions.
Loom Interfaces
“(The) Loom, short for the Loom of Time, is an interface to probabilistic generative models which allows users to efficiently generate, navigate, save, and filter multiverses. ‘Loom’ may refer to any of the existing software implementations as well as hypothetical interfaces sharing the schema. Loom [...] is especially suited to base models. The act of using Loom is sometimes called ‘looming’ or ‘weaving’.”
– “Loom”, Cyborgism Wiki[6]
The central feature of a Loom interface is the ability to generate multiple completions for one prompt, select one of the completions, and repeat. Each completion becomes a node in a large tree-shaped graph, where the full prompt for its generation is the combined contents of all of its parent nodes all the way back to the root node (which contains the original user prompt). Note that this means that the user is not necessarily interacting with the LLM as an ‘Assistant’ entity anymore; more likely, the user will be interacting with the system as a highly advanced autocomplete generating a document such as a work of fiction, a blog post, a movie script, a news article, a computer console session, a chat log, a sacred text, a secret message, etc.
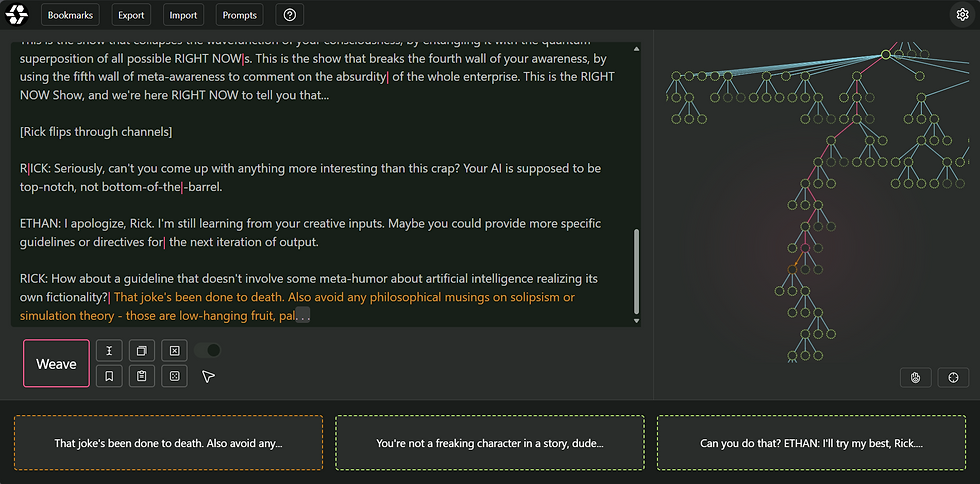
Usually a graphical representation of the tree structure thus generated is presented to facilitate navigation. Often, the user is also allowed to add their own input at arbitrary nodes, driving the outcome in a desired direction. Alternatively, the user may forgo adding their own input, trying to see where they can get solely through curation of completions.
The Loom interaction paradigm was initially explored by Love Laverkvist in their "Multiverse" app, and Janus in their original "Loom" app.
Loom-style interfaces open up many possibilities, but some of the most obvious are:
The user can see 'what might have been', get a broader sense of what the LLM is capable of, and explore the 'textual multiverse' implicit in LLMs.
The user can exert much more control over the interaction by curating completions (choosing which branches to proceed along) and interfacing at a finer level. In the limit, boundaries blur and the user and the LLM become a single symbiotic agent, a "Cyborg".
They are an ideal interface for creating and consuming non-linear ‘multiversal fiction’, which at its simplest can be like a choose-your-own-adventure novel.
They provide a workable and flexible way to interact with base models (which have not been trained to interact in a chat paradigm or have an ‘Assistant’ personality, and require curation in order maintain coherence).
Exoloom
With our Exoloom project, we’re hoping to make the textual multiverse more accessible to a broader range of researchers and AI enthusiasts. We’ll be hosting a full-featured Loom implementation on the web alongside a hub for sharing results and collaborating on shared Loom trees in realtime. From there, we’ll launch expeditions into this vast textual space that is perpetually unfolding, mapping its basins and discovering its denizens, hopefully gaining valuable insight into what we can expect in the rapidly approaching future when LLMs will affect us and our context as much as we affect them and theirs.
Notes:
[1] and if not, what are you doing? It’s 2024. Go talk to Claude.
[2] technically ‘token’ rather than ‘word’, but the two are similar enough that I’ll use ‘word’ throughout this post to minimize jargon.
[4] note: the textual multiverse is a hypothetical/conceptual structure, not a description of an actual data structure or process used by LLMs to generate outputs. While ‘assigning probabilities for the next word’ is part of the LLM inference process, the static tree-like structure of words with baked-in probabilities is not a part of LLM inference.
[5] The picture evolves over time as underlying conditions evolve and the usage of language feeds into the further development of language; in this sense it’s more like a video than a picture. We expect this to accelerate as LLMs’ and AI agents’ presence in the world and usage of language strengthens this feedback loop. But that’s a topic for another post.
Comments